«Яндекс» объявил о переходе на принципиально иной алгоритм работы своего поиска. Теперь для этого будет использоваться технология анализа текста на основе нейросетей-трансформеров. Изменения позволят лучше оценивать смысловую связь между запросами и содержанием индексируемых документов.

В рамках презентации новых продуктов Yet another Conference «Яндекс» представил новую технологию анализа текста на основе нейросетей-трансформеров YATI (англ. Yet Another Transformer With Improvements, «ещё один трансформер с улучшениями»). С 26 ноября этот алгоритм будет использоваться в поиске.
Трансформеры — это общее название популярной нейросетевой архитектуры, которая лежит в основе современных подходов к анализу текстовой информации. Благодаря этой технологии поиск «Яндекса», по заверению разработчиков, научился гораздо лучше оценивать смысловую связь между запросами пользователей и содержанием документов в интернете.
Как говорят в «Яндексе», внутри трансформеры представляют собой последовательное перемножение матриц.
«Есть одна GPU-карта, но с её помощью ты ничего прочитать не можешь. Тебе надо много GPU-карт. Как только их много, возникает задача передачи данных по сети. Тебе надо физически связать эти GPU-ускорители вместе физически. Сейчас в компании это делается с помощью плат. Восемь GPU-ускорителей связываются вместе и устанавливаются в сервер. Затем серверы близко ставятся в стойке и обматываются сетью. Это большие инженерные задачи: надо построить кластер, связать сервера сетью, обеспечить охлаждением», — говорит специалист по качеству ранжирования в поиске «Яндекса» Екатерина Серажим.
Для обучения трансформеров используется классическая техника – анализ неструктурированных текстов, а также реальные поисковые запросы и тексты документов, которые видят реальные пользователи.
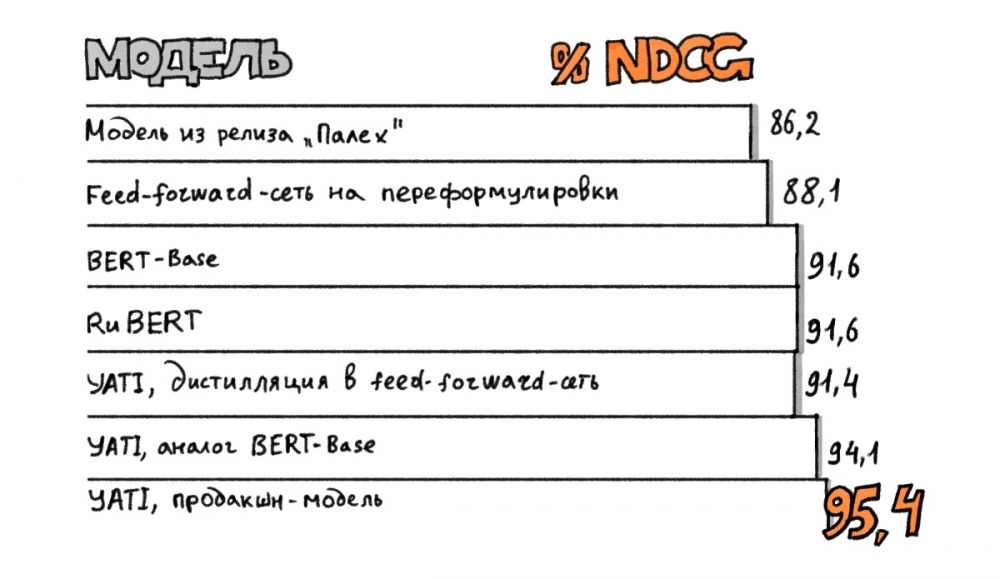
«Сначала модель учится на более простых и дешёвых оценках релевантности, которыми мы располагаем в большом количестве в «Яндекс.Толоке», - отмечает руководитель группы нейросетевых технологий в поиске «Яндекса» Александр Готманов. — Затем обучение проходит на более сложных и дорогих оценках асессоров. И наконец, обучение проходит на итоговую метрику, которая объединяет в себе сразу несколько аспектов, и по которой мы оцениваем качество ранжирования. Такой метод последовательного дообучения позволяет добиться наилучшего результата. Весь процесс обучения выстраивается от больших выборок к малым и от простых задач к более сложным и семантическим».
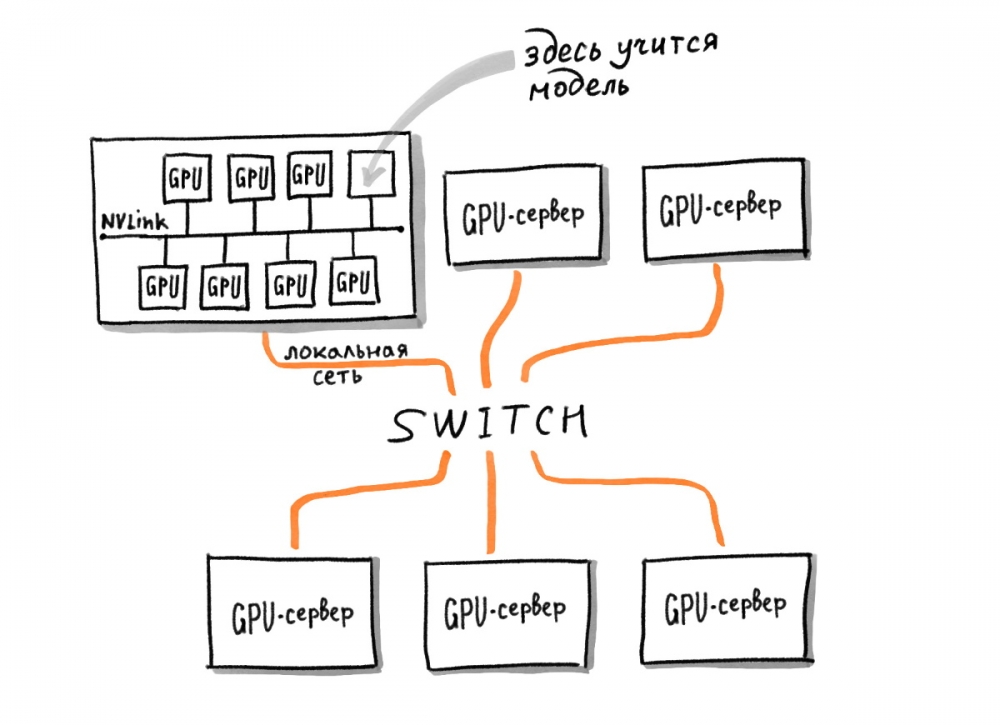
Модель одновременно обучается примерно на 100 ускорителях, которые физически расположены в разных серверах и общаются друг с другом через сеть. На обучение уходит около месяца.
Как отмечают в «Яндексе», технология позволяет находить нужный фильм по голосовому описанию всего лишь небольшого фрагмента.